Distribution of token lengths with respect to the tokenizer vocabulary size - Part 2
So last time we analyzed the token length distributions of tokenizers with various vocabulary sizes. The tokenizers were trained on about 30Mb of data, and so I wanted to see if the observed effects persisted with more data!
I started by donwloading about 20Gb worth of wikipedia articles (about half of the "wikipedia/20220301.en" Huggingface dataset). Starting the tokenization training process for a single tokenizer for such a dataset was estimated by tqdm to take about 10 hours on a Standard NC6s v3 (6 vcpus, 112 GiB memory) Azure virtual machine. So I set it to run overnight, and noticed that the process had been killed a quarter of the way in.
So the gut feeling is that maybe if a quarter of the 20Gb dataset kills the system, then maybe less than 5Gb would be doable. To play it safe, I deleted about 90% of the data, i.e. dropped to 2Gb. The tokenization trainings still take time, but now training e.g. 30 tokenizers takes a few hours instead of days.
Let's plot similar images as before:
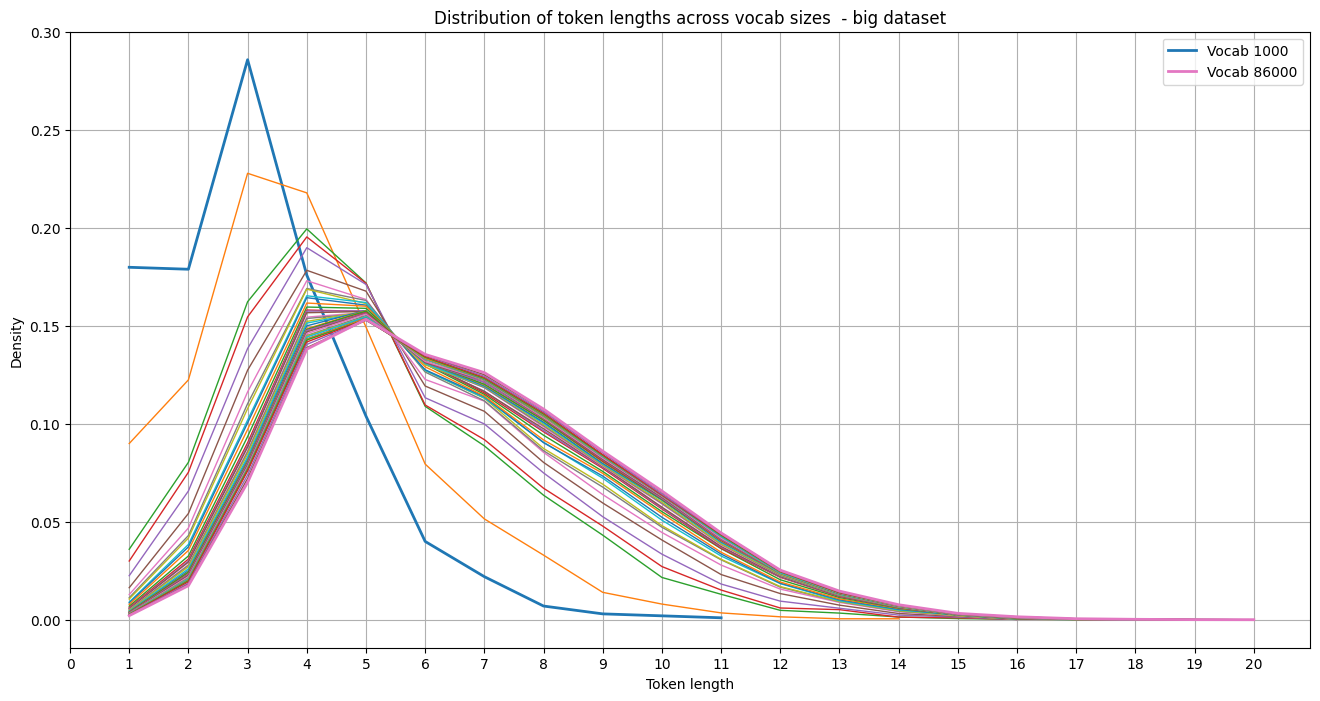
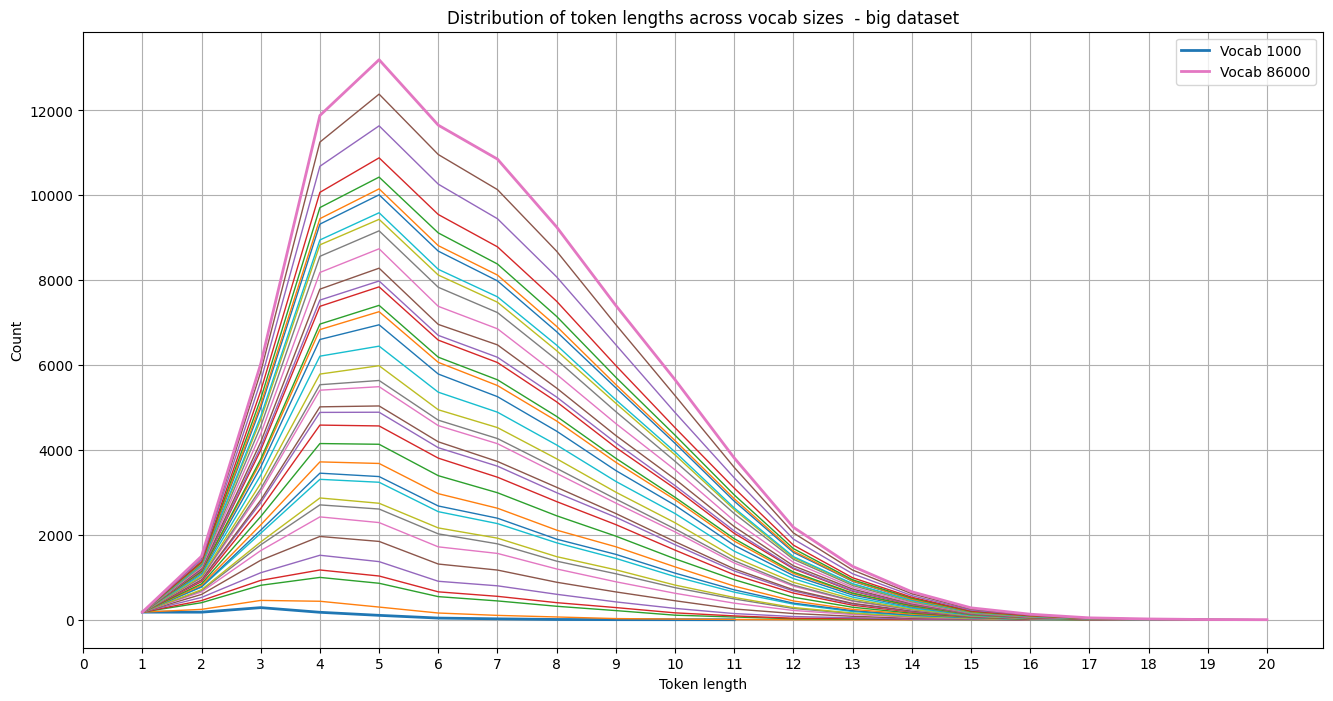
So it seems that the same basic trend is visible. Though if we compare the distributions of the tokenizers trained on the small and large dataset per vocabulary size, interesting images emerge:
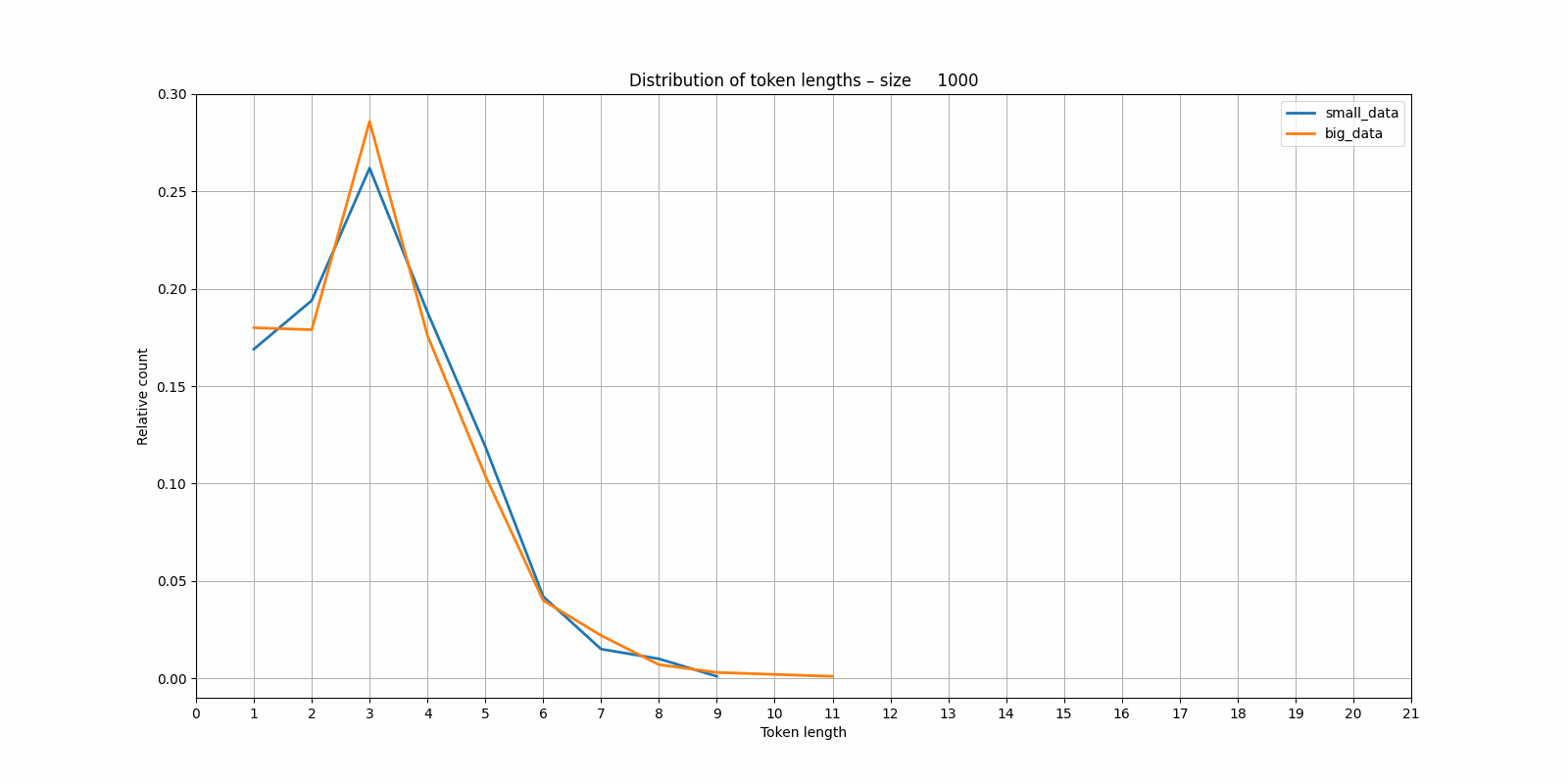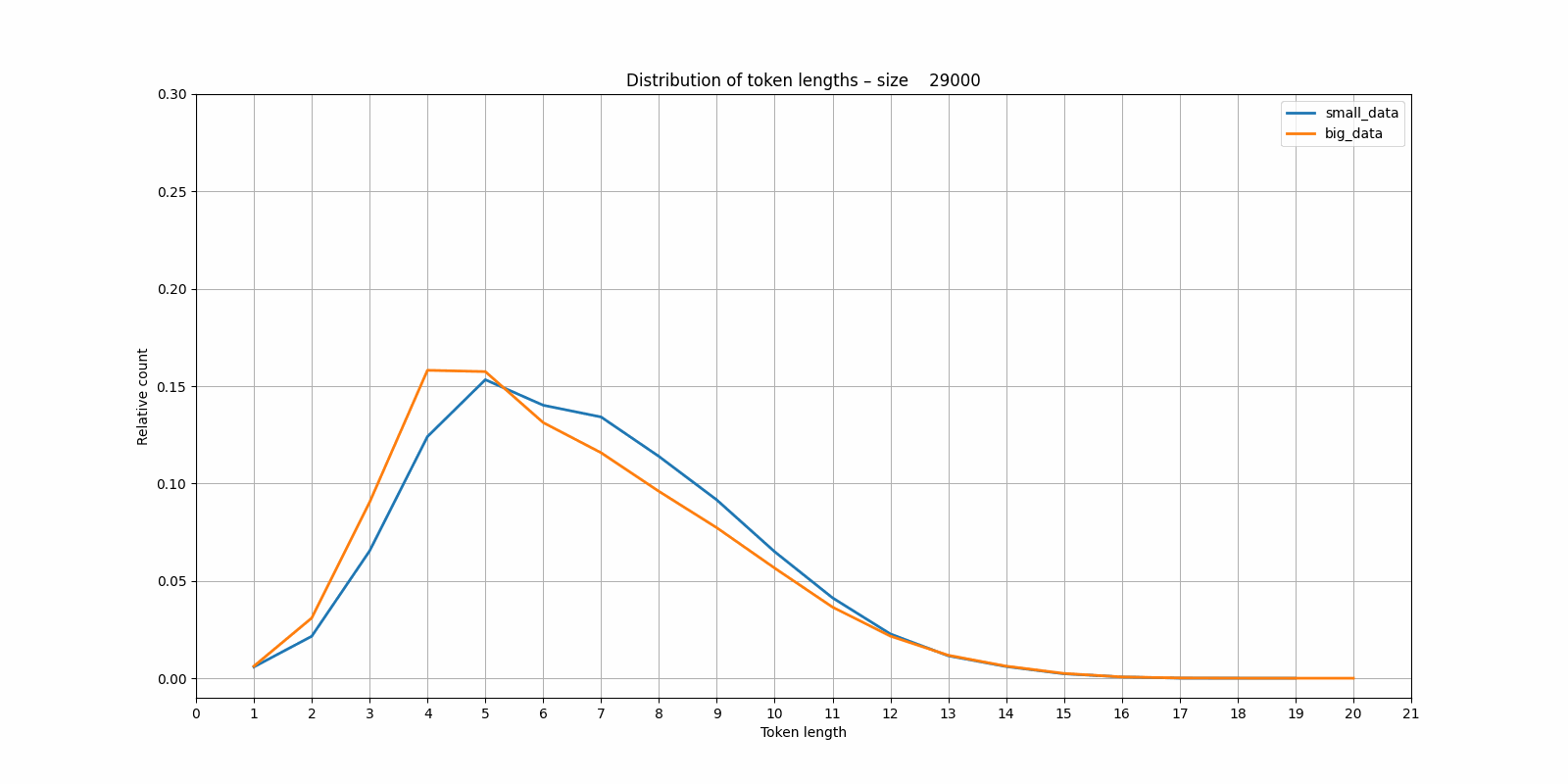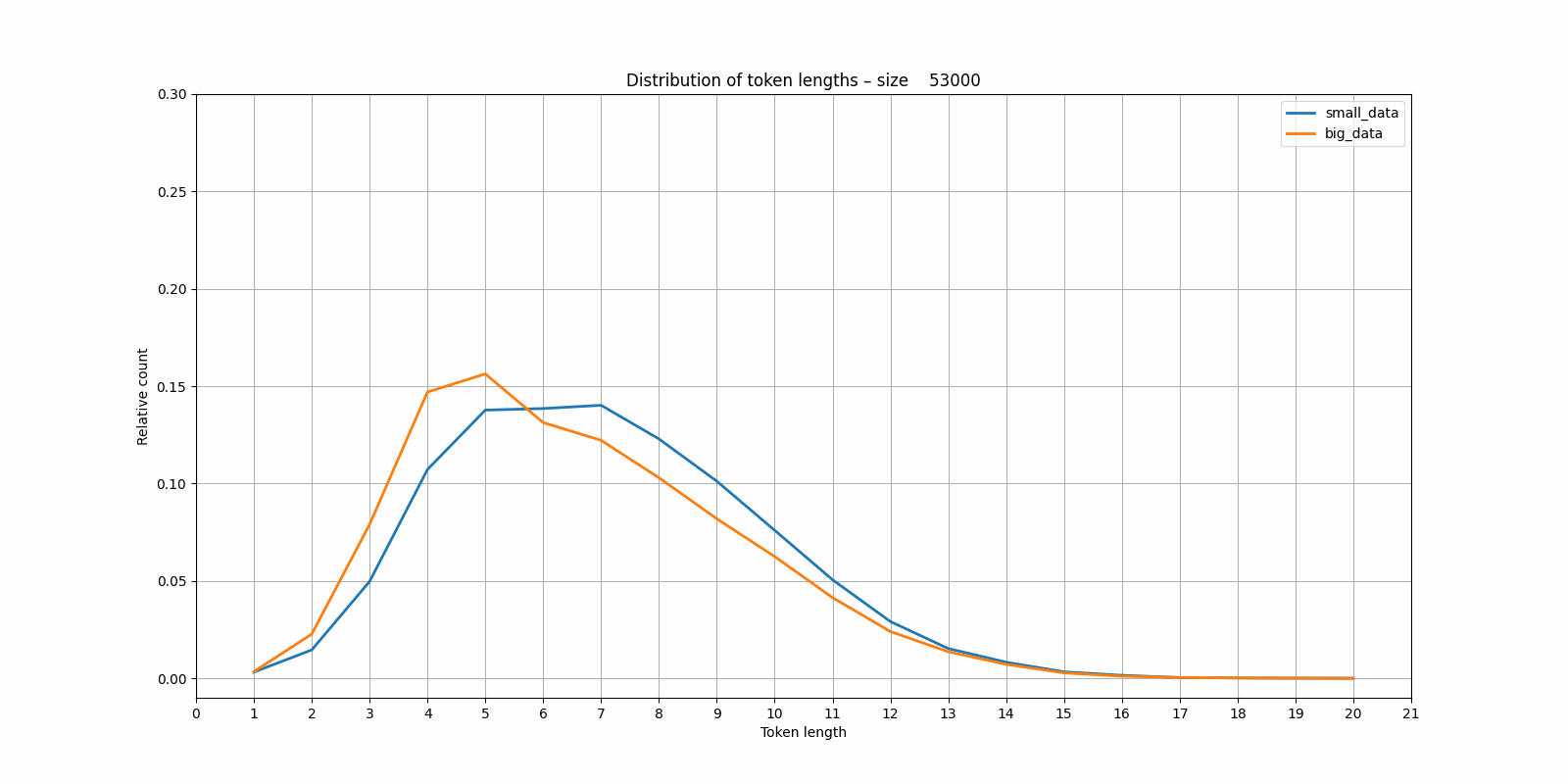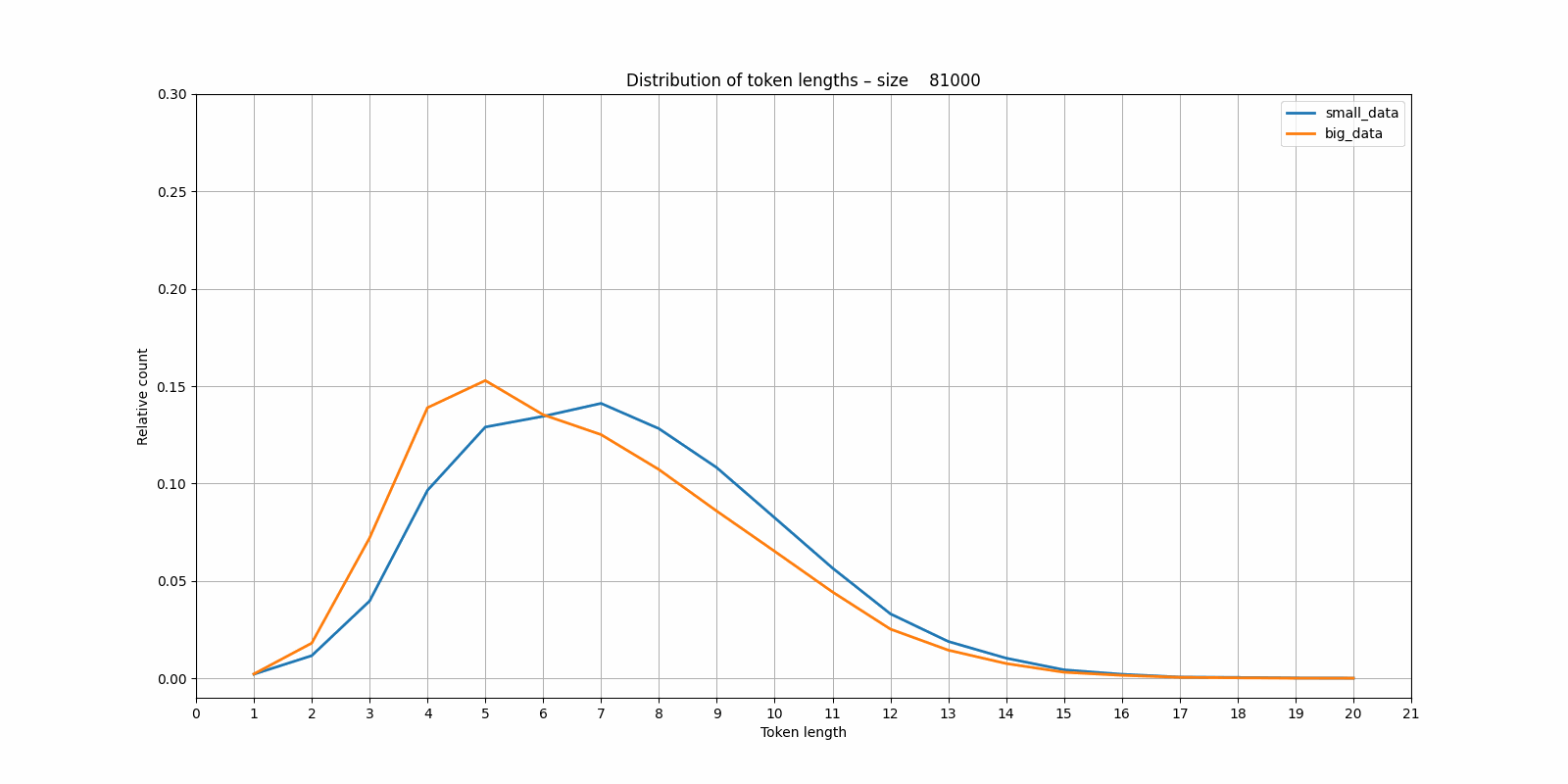

It seems that the tokenizer trained on the small dataset is more "eager" to start creating larger blocks than the one trained on the larger (and more variable?) dataset. Again I have the nagging feeling that this would be obvious if I'd studied BPE tokenizers in more detail.